计组笔记:第四章-存储系统
4.1.概述
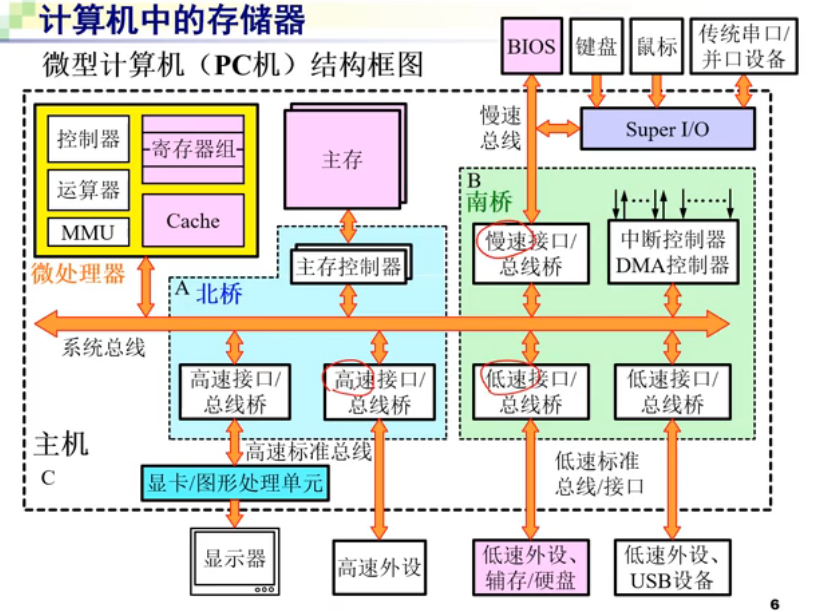
CPU通过总线,和系统中各部分组件相连接。和它连接的硬件,其中就有一组由各部分组件构成的一个存储系统。此外还有其他通过“接口”和总线相连接的外设。接口中有着一些可编程部分,它们负责统一总线通信协议。
BIOS存储在一个固化的存储芯片中,负责引导系统开机。引导系统加载后,它跳转到系统的内存位置,结束任务。操作系统则负责加载自己的其余部分。
在这个过程中,CPU先从Flash取指令,再从主存MM中取指令,其中也会从硬盘加载指令来执行。
4.1.1.存储系统的层次结构
系统的存储体系属于金字塔型多级结构。从寄存器到Cache,MM,ROM,磁盘,设备的存储速度逐步下降,价格也逐步下降,存储空间也逐步增加。而这整个体系对于CPU而言是一个完整的体系,它们具有寄存器的速度,也具有磁盘的大容量。这就是依靠存储体系实现的。典型的存储体系是一个三层结构。
存储器的三大要求:大容量、高速度、低成本。这三者往往是矛盾的。
本章的重点是Cache部分
CPU中的寄存器一般使用触发器实现。它集成度最低,容量最小,但是速度也最快。Cache使用SRAM实现,MM使用DRAM实现,BIOS使用ROM实现,辅存使用HDD实现,还有其他脱机存储器,比如磁带,光盘等。
现在,CPU内部的Cache也有多级缓存结构,例如L1 Cache,L2 Cache,L3 Cache。
系统的总线分为北桥和南桥,前者速度比较快,跟CPU相连更近;后者离CPU更远,因此更慢。不过现在南北桥已经集成到SoC(System on Chip)了,两个已经合成一个芯片。
一般存储体系有两种:
- Cache存储体系 由Cache和主存构成,主要为了提高存储器速度;对系统程序员以上均透明(不可见)
- 虚拟存储器系统 由主存和磁盘构成,主要是为了扩大容量;对应用程序员透明
透明的说法在这些计算机的书里很流行,它的意思不是说可见,而是说它本身和一块玻璃一样,不可被看见。
存储器分类
分类标准:介质、用途、信息易失性、存取方式(随机,例如RAM;顺序访问,例如顺序存取存储器SAM,直接存取存储器DAM)、读写功能(读写,只读)。
也可以如下分类:
- 基本型存储器
- 半导体
- 易失RAM
- S(Static)RAM
- D(Dynamic)RAM
- 非易失ROM
- EPROM紫外线擦除
- EEPROM($E^2ROM$)电擦除
- Flash闪速
- NOR随机访问,可存储固件
- NAND只能顺序存储,可以做大容量存储器
- Flash闪速
- 易失RAM
- 磁:磁盘
- 半导体
- 复合型存储器
- 半导体:多端口、多体交叉、相联
- 磁:磁盘阵列(RAID)
4.1.2.存储器的性能指标
容量、速度(存取时间;存取周期;存储器带宽,单位时间存储器可以读出/写入的字节数,$B_m=\frac{n}{t_m}$,分子是每次读写字节数,分母是存取周期)、可靠性、功耗、价格、体积、重量、封装方式、工作电压、环境条件等。
4.2.1.随机读写存储器RAM
- 内部译码结构:
- 一维译码:使用类似74138的译码器将地址对应到存储单元
- 二维译码:一个行选,一个列选,适合大规模存储器的译码
- 单元电路
- 静态读写存储器SRAM
由6个晶体管实现,只要不断电,信息不丢失。初始加电,状态随机。电路中总有晶体管导通,功耗大,集成度不高。
2. 动态读写存储器DRAM
四个晶体管实现。内部由电容维持电荷,因此需要定时读取刷新来保持数据。功耗低,集成度高。现在更新的DRAM可以只用一个晶体管和一个电容来实现,因此可以有更高的集成度。通过SenseAMP,可以根据电压变化来刷新存储器的内容。
3. 内存构成
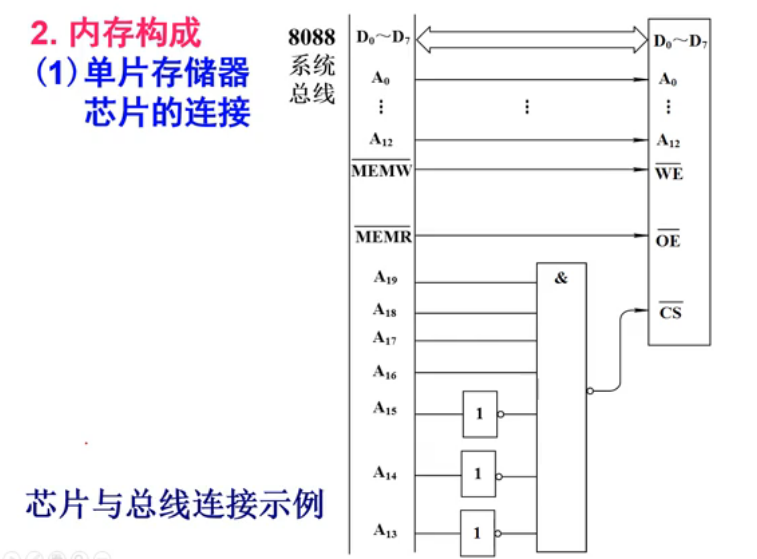
1. 单片存储器芯片的连接
引脚定义:Dn是数据线,An是地址线,OE是读开关,WE是写开关,CS是控制开关,也就是片选端口。
连接方式如图所示,特殊的部分主要集中在片选端口上。这部分电路叫做内存地址译码电路,它负责选择不同的芯片。注意,上划线的是低电平有效端口。
这里的重点就是地址范围分析。这个很简单,只需要让CS为低电平的信号作为高位,再去看低12位的地址总线就能看出来地址范围了。比如,下图的地址范围就是F0000H~F1FFFH这个地址范围。
2. 内存的字扩展
使用$8K*8bit$的SRAM去构成32KB的内存,只需要让二者的位数对应上就行。比如这里就只需要4个这种规格的SRAM芯片。如下所示:
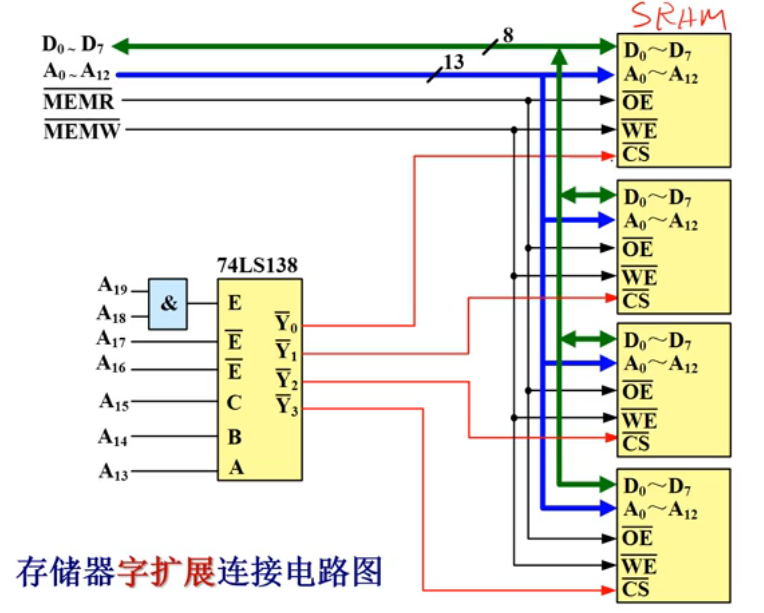
所有芯片的Dn和An、OE、WE都并联。而CS则由74138控制片选情况。这时就可以分析得到,从上到下四个芯片的地址范围分别是C0000C1FFF,C2000C3FFF,C4000C5FFF,C6000C7FFF。这称为字扩展。
3. 内存的位扩展
例如,用$2K4bit$的存储芯片构成$2K8bit$的存储芯片。这种接法如下图所示:

也是用74138去进行片选,同时BHE也需要控制。
这里经常会有内存范围的计算。计算地址范围的大小时,记得大地址减去小地址后加一。例如78000H到97FFFH,计算时就应该是用$98000H-78000H=20000H$,也就是$2^{17}$字节(一般都是按字节编址),因此需要$(2^{17}\div 2^{10})KB\div 2KB=64$片这样的芯片。
可以参考这个例题食用:

4.2.2.只读存储器ROM
- 特点:存储信息的非易失性
- 分类:
- 掩膜型ROM
- 可编程ROM:PROM、OTP-ROM
- 可擦写编程ROM:(UV)EPROM、EEPROM、Flash(NOR、NAND)
4.2.3.动态存储器
- 一般的动态存储器DRAM:以Intel 2164A为例
无论读写,地址都需要分两次来送。第一次时,给RAS一个下降沿,第二次,给CAS一个下降沿,来让芯片读取这两个地址。得到地址之后,芯片把数据送出数据线。这和如今的DRAM芯片一致。它每隔2ms刷新一次。只需要给RAS一个下降沿,就能刷新一行的DRAM。
这里可能会考到引脚相关的问题,如下所示:

- 常用刷新方式:
- 集中式:有概率会遇到死区(不可用时段),因为刷新时间会集中占用一个时段
- 分布式:更短的刷新周期,将刷新的周期均匀分布到读取时间段。但是内存访问时延变长了
- 异步式(最常用):$Row\div T_{Refresh}$得到周期,再在每个周期最后刷新内存。它将刷新安排在指令译码阶段,不会出现死区。
- 同步动态存储器SDRAM
DDR SDRAM:上升和下降沿都能读写数据。
4.2.5.其他存储器
- 多端口存储器:DS1609,有两个数据端

多体交叉存储器:并行,提高读写性能
- 多体并行访问:80x86处理器内存组织
- 多体交叉访问:类似流水线的重复设置瓶颈段的操作,能大大提高性能。连续读m个数据,需要的时间:$T+(m-1)\cdot \Delta t$。类比于流水线的加速比,它也有加速比,$B=\frac{1-(1-\lambda)^m}{\lambda}$。标量机中,m取2~8;超量机中,主存分体数可以超过32
相联存储器:一种多路选择器构成的Key-Value形式存储器
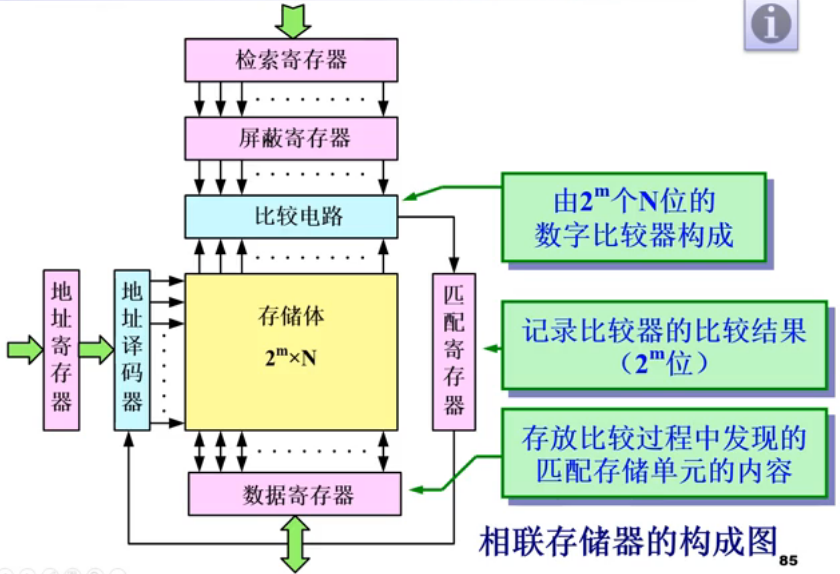
它的用途有:Cache的目录表、页表的块表(TLB)等。
4.3.高速缓冲存储器
它是实现金字塔型存储体系的关键所在。它可以将上一部分频繁使用的部分存放在其中,以此来提高性能(这是因为它本身的速度就很快)。
局部性原理:时间/空间局部性,相关的变量,会在时间/空间上存在局部性比如循环变量,会存在时间局部性;相邻的数组元素,存在空间局部性
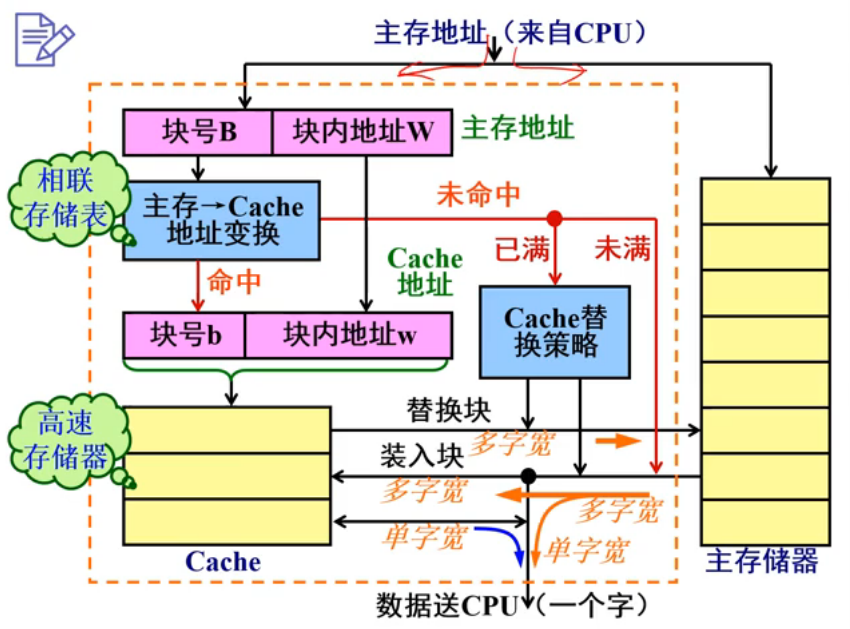
上面是Cache的作用:命中的话,直接使用;未命中Cache,则访问主存,并改动Cache。这一步得注意,由于Cache存在,就出现了数据不一致性,因此得控制好数据写回时机来保证数据一致性。
4.3.2.地址映射
- 地址映像 就是把主存上的数据按照某种规则装入Cache,并建立主存和Cache地址间的映射。
- 地址变换 使用Cache中数据之前,必须先把程序从主存地址变换成Cache地址才能使用。
- 选取地址映射的原则:
- 地址变换硬件要高速、低价、易于实现
- Cache空间利用率要高
- 发生块冲突概率要小
- 这种映射的调度单位是块。
映射方式一般有三种:全相联、直接映射、组相联。
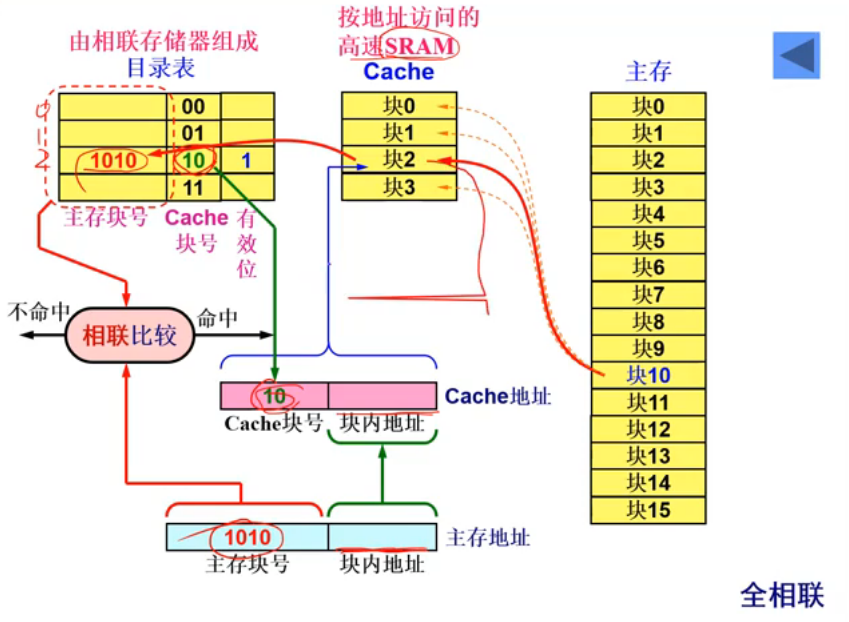
- 全相联:主存的任意一块可以映像到Cache的任意一块(可以认为是完全自由的装法)。具体如下图所示:
- 直接映射:按照Cache容量对主存分区,一个区的块只能装入一个Cache的对应位置。不过这里得注意,目录不存块号了,存的是区号。块号在Cache开头存着。
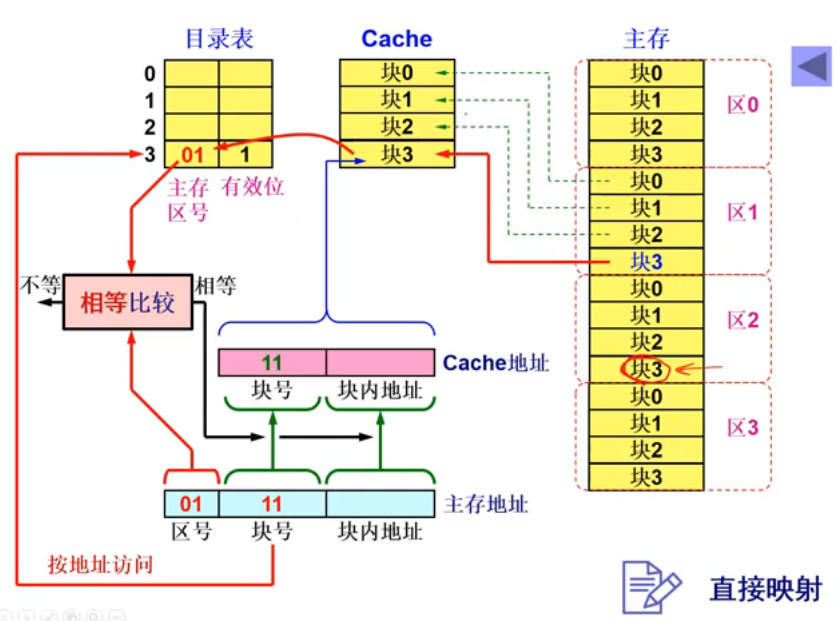
这样的好处就是,不用相联存储器,访问速度也快(不需要地址变换)。不过缺点也很明显:Cache块利用率低,块冲突概率高。特别是,如果主存存储的变量具有空间相关性(比如数组),那这一个Cache位置几乎每次访问都不会命中了。
- 组相联:跟上面一样,将主存按Cache总大小分区,每个区内部按照Cache规则分组,每个组中有若干块。具体如下图:
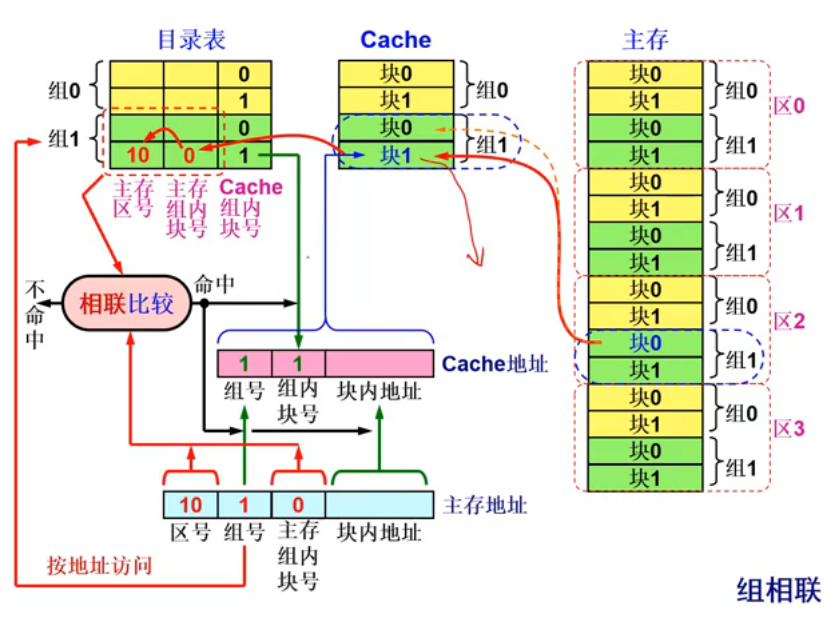
它是前两者的折中,优点是提高了利用率,降低了冲突率,也大幅降低了失效比率。但是问题是制造成本和难度上升了。
做题时,要解决Cache分块,只需要把主存地址按照每个编号类型的长度来划分就行。

4.3.3.替换算法
直接映射不需要替换算法。全相联、组相联有如下几种替换算法:
- 随机替换算法
- 先进先出替换算法(FIFO)
- 它还有一个二次机会的版本
- 最不经常使用替换算法(LFU):总的使用频次最少,实现困难
- 近期最少使用替换算法(LRU):上一次使用的时间点最晚
- 最佳替换算法(OPT):预测将来的情况,根据将来的情况替换。作为其他算法的性能基准
关于一致性问题有两种策略:写回法,只有Cache被替换时才将它写回;全写/写直达法,写入Cache时顺便写入主存,如果未命中,则直接写主存,然后根据WTWA/WTNWA(写分配/不分配法)来决定是否将块取到Cache。前一种方法高性能,后一种主存一致性好。

4.3.5.Cache性能分析
- 加速比
- Cache-主存系统的平均访问时间(周期)$T_A$:
- $T_A=H\times T_C + (1-H)\times T_M$
- $T_A=H\times T_C + (1-H)\times(T_B+T_C)=T_C+(1-H)\times T_B$
- Cache-主存系统的平均访问时间(周期)$T_A$:
其中,$T_C$和$T_M$分别是Cache和主存的访问周期,数据块装入Cache的时间是$T_B$,Cache的命中率为$H$。当命中率很高时,$T_A \to T_C$。
上面的两个等式,对应的分别是1,2两种情况。第二个式子的考量就是,如果没有命中缓存,则耗时为缓存装入时间加上缓存访问时间。

例如,假设$H=95%,T_M=100ns,T_C=10ns$,则可得$T_A=14.5ns,S_P=6.9$。其中的$S_P$就是加速比,定义为$S_P=\frac{T_M}{T_A}$。
- 成本
$C=(C_1\times S_1+C_2\times S_2)/(S_1+S_2)$,也就是主存价格*主存容量+缓存价格*缓存容量
命中率与Cache容量的关系:
$H=1-S^{-0.5}$
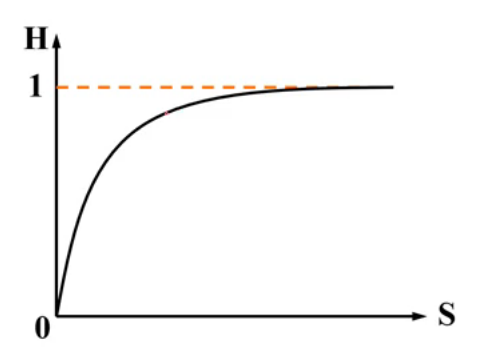
这给出了Cache容量的合理考虑区间。
- 命中率与块大小的关系

- 两级Cache
未命中率(失效率):$\text{总失效率}=\text{失效率}_\text{第一级} \times \text{失效率}_\text{第二级}$
4.4.虚拟存储器
高速的主存容量不能满足要求,因此开发出了虚拟存储器(软件实现)。
CPU集成的:Cache,MMU等。这些为主存的实现提供了基础。
虚拟存储器=主存储器+外部存储器+辅助硬件(MMU)+系统软件(OS)。而虚拟地址得先转换成指向真实物理内存的物理地址才能拿来使用(地址转换)。
地址映像:全相联;地址变换:MMU。虚拟存储器相当于内存扩展的一种实现手段,通过将内存映像到磁盘上,模仿Cache的原理,以此扩大主存容量。
这其中涉及三种地址空间:
- 虚拟地址空间:编程中用到的
- 主存储器地址空间:物理地址
- 辅助地址空间:磁盘存储器的地址
因地址映像和变换方法不同,存储方式分为段式存储、页式存储、段页式存储。
- 段式存储:每个程序段从0开始编址,长度不定。如下图,把数据分段,再把数据装入内存。对于不常用的段,系统会把它放入磁盘。
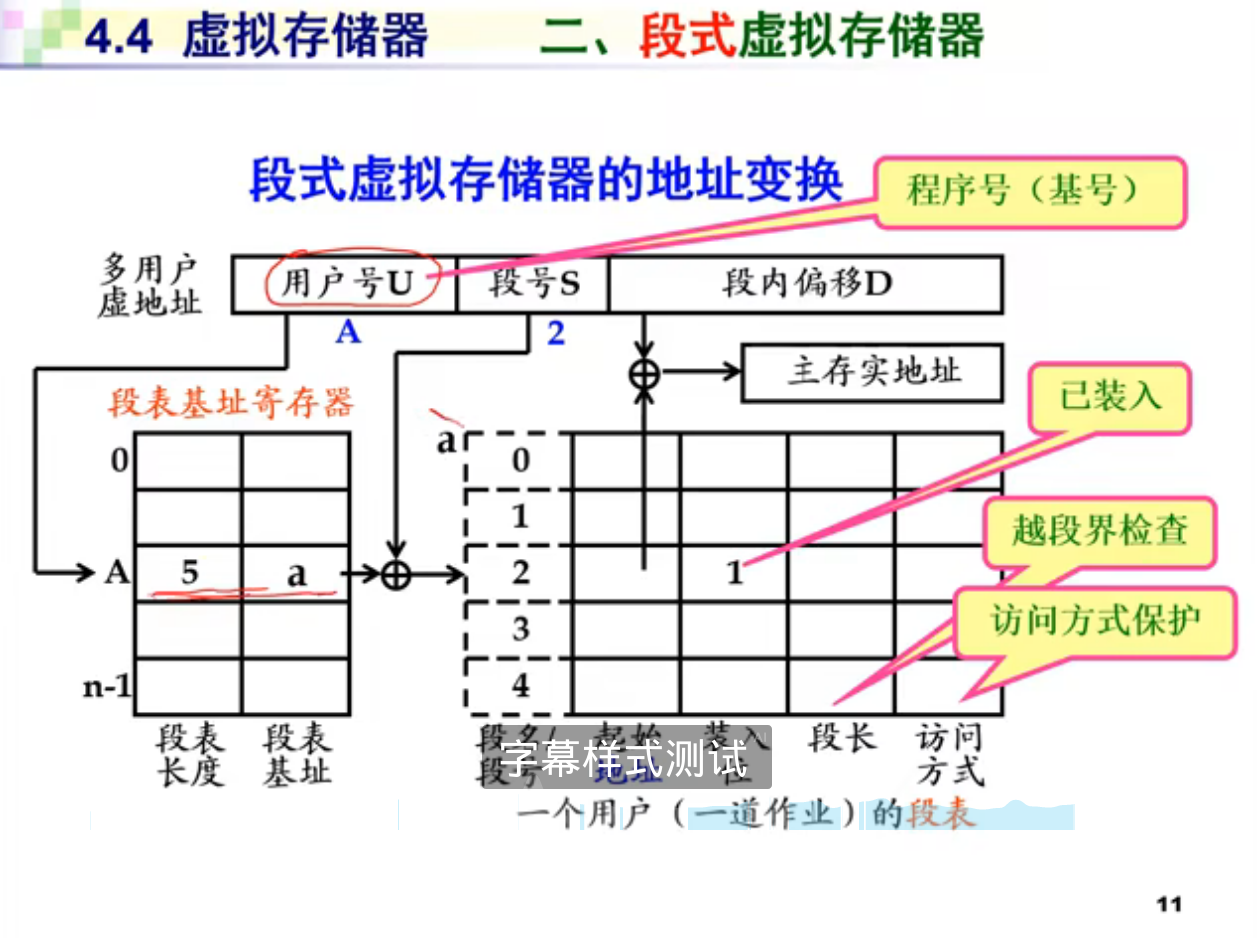
缺点有俩。一个是太慢了。因为得做两次运算;另一个是,页表太大了。
- 页式虚拟存储器:跟上面一样,分页,页大小固定。
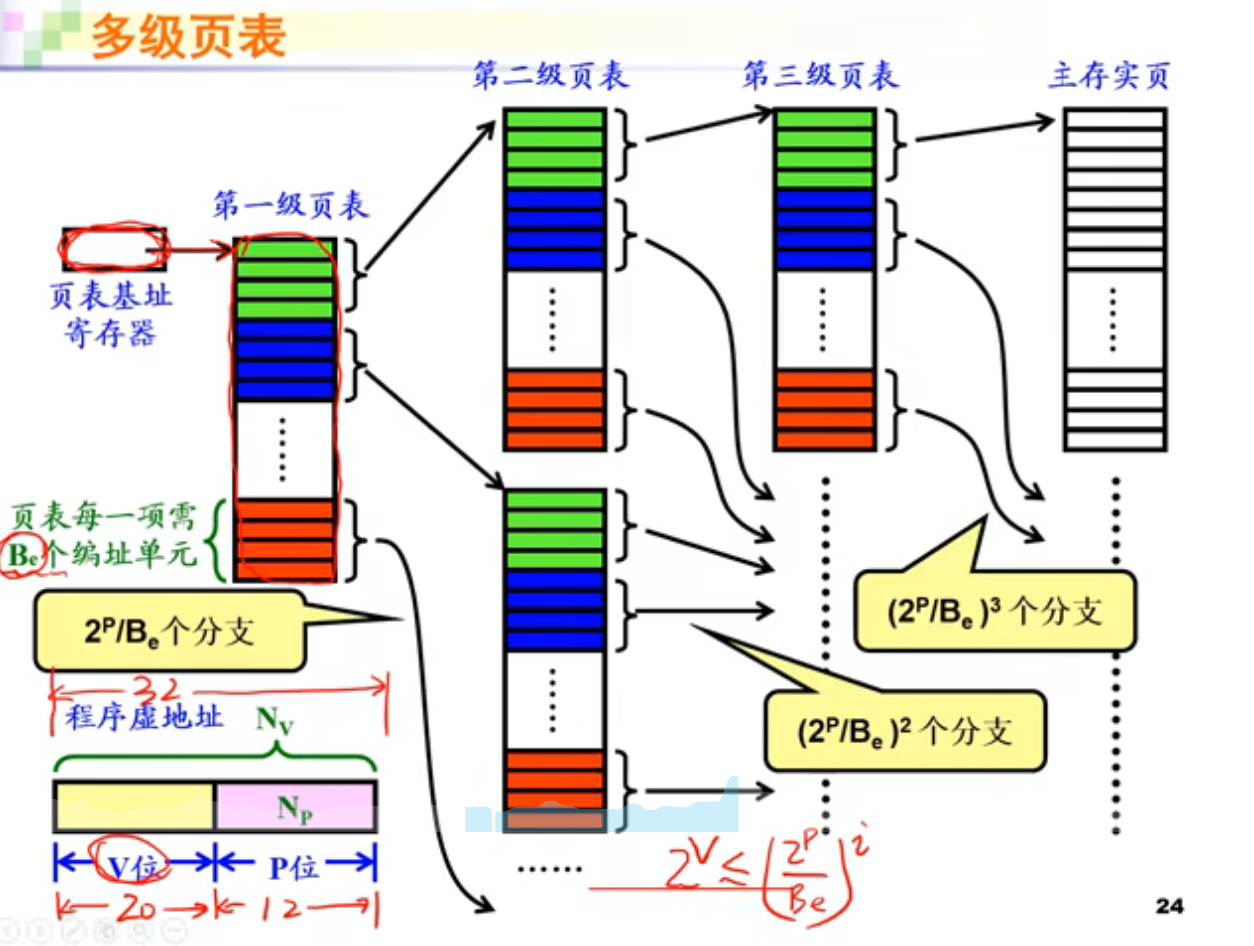
它的缺点很明显。当地址空间过大时,它的体积会很大。为了解决这个问题,出现了多级页表。
- 段页式存储器:先分段,每个段再分页。这需要段表和页表,它们都由操作系统管理。
由于页表本身很大,因此引入了一个CPU内部的Cache用来存储TLB,而慢表存储在主存中。虚拟地址和Cache地址一样,也是把物理地址转化来得到的。每一个段的大小是4KB,页则是由若干个段构成。段有额外的位用于标记读写执行情况。段内有偏移,页内也有偏移。
注意:页/段页都是以页为基础单位来和磁盘交换数据的,只有段式是以段为单位和磁盘交换的。
页表级数为i,则$\frac{2^P}{B_e}^i=2^V$,简化得:
$$
i=\frac{log_2 2^V}{log_2 2^P-log_2 B^e}=\frac{V}{P-log_2 B^e}=\frac{V}{P-N_e}
$$
其中,$V$是虚页号的位数,$P$是页内偏移的位数,$N_e$是页表每一项需要几位编址。
4.5.外存储器
磁盘特点:
- 优点:存储容量大,单位价格低、记录介质可重复使用、可长期脱机保存、非破坏性读出
- 缺点:存取速度慢、机械结构复杂、工作环境要求高
- 磁记录原理
- 写入:磁头通不同方向的电流,就能在磁化材料上留下不同方向的磁场。
- 读取:原来是磁头切割磁感线,电流方向就是信息。现在是GMR效应,读取使用单独的头,能实现更高的容量。从LMR到垂直记录技术(PMR)的改进也大幅提高了磁盘容量。
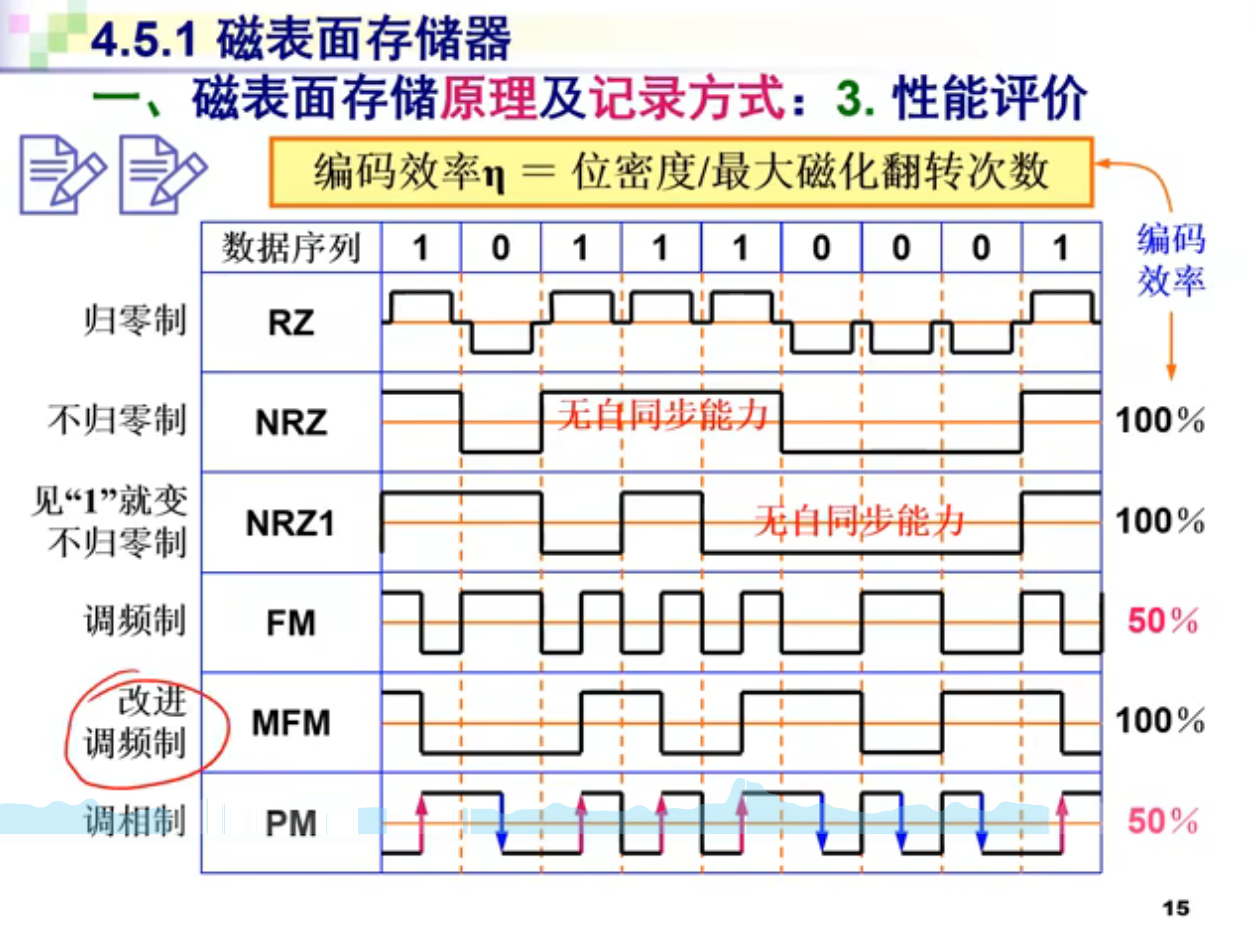
记录方式,和计算机网络中的编码是相似的,有RZ,NRZ,NRZ1,FM,MFM,PM等:
这是磁盘的结构,一般民用磁盘大气压和外界一样的,高速旋转时,会在表面形成气垫,托起磁头。

- 硬盘的数据记录格式
- 磁盘内部物理地址
- 柱面 Cylinder
- 记录区 Head
- 扇区 Sector
结构方面,单个面分为一个一个的环,称为磁道(Tracks)。几个盘面上的同位置的磁道组合起来称为一个柱面(Cyinder)。磁盘上一个扇形区域称为一个扇区(Sectors)。
- 主要技术指标
- 道密度:道/mm,道/英寸
- 位密度:bit/mm,bit/英寸
- 存储容量
- 非格式化容量=位密度x内圈磁道周长x每个记录面的磁道数x记录面数
- 格式化容量=每个扇区的字节数x每道扇区数x每个记录面磁道数x记录面数

存储容量如上,有两种。早期为方便管理,将所有磁道等分为相同的扇区数。磁道外圈可靠性最高(因为外圈的词单元尺寸最大,所以最可靠),从外圈开始编号。
- 平均访问时间:平均寻道时间+平均等待时间(转半圈的速度)+数据传输时间,是毫秒级别的参数。
- 转速:RPM(转/分钟)
- 数据传输速率:磁头找到数据地址后,单位时间读/写的字节数。计算方法为:$\text{每个扇区的字节数}\times\text{每道扇区数}\times\text{磁盘转速}$

上面是2001年生产的硬盘参数,能从参数看出磁盘对加工精度的极高要求。下面是一个硬盘容量计算的例题。

受限于磁盘的物理原理,磁盘的随机访问性能相对比较差。因此,引入了磁盘阵列RAID。
4.5.1.磁盘阵列RAID
这部分内容了解就行(
不了解也行
作用就是通过设置重复设备,来提高整体的性能和可靠性。详细可以看这本书:

RAID全称呼:独立冗余磁盘阵列(Redundant Array of Independent Disks)。不过刚开始I表示的是Inexpensive,廉价。
RAID0:无冗余

性能高,但是可靠性不高。并且需要至少两块硬盘。
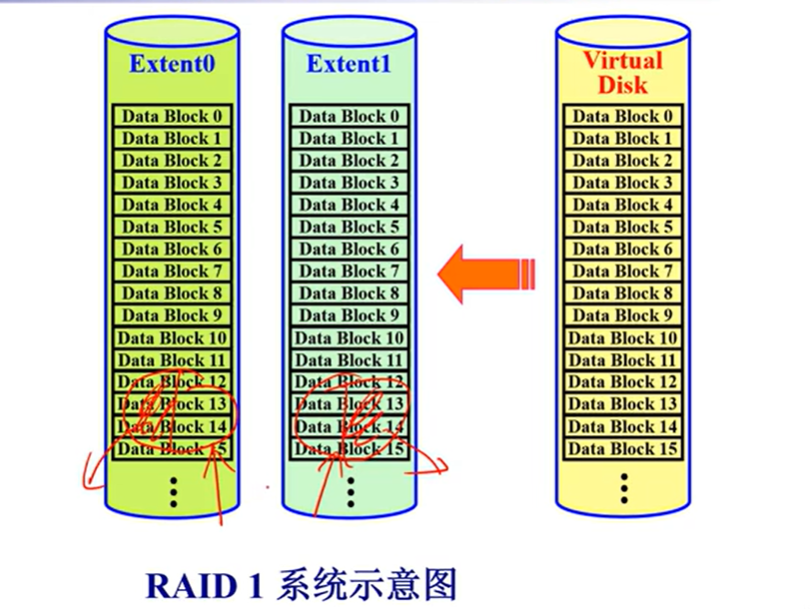
RAID1:两块盘互为镜像
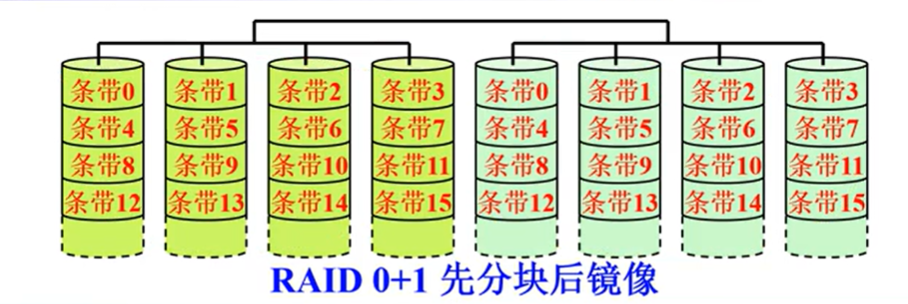
RAID0+1/RAID01
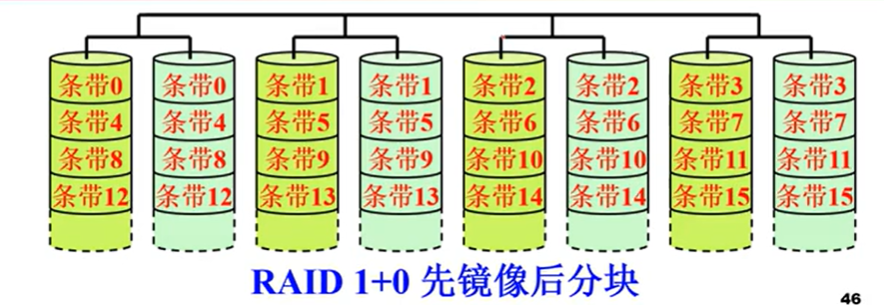
RAID1+0/RAID10
RAID2:冗余使用汉明码

RAID3:位交错奇偶校验

不能并发读写
RAID4:块级奇偶校验

可以并发读取,不过不能并发写入。
RAID5

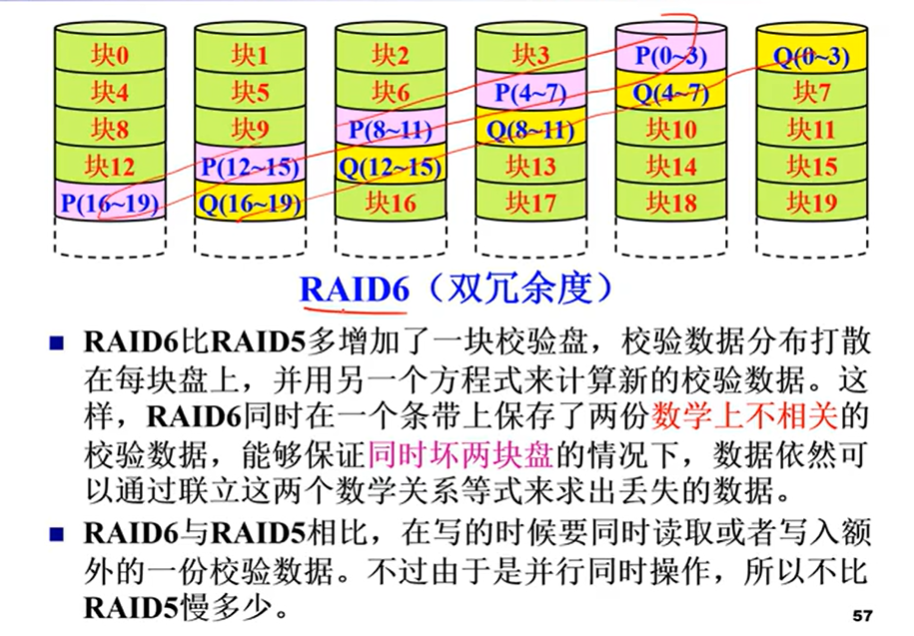
RAID6

4.6.Cache一致性协议
了解就行